在微信公众号内容采集领域,传统工具如Jina和FireCrawl面临高达40%的失败率(数据来源:2025年网页爬虫技术白皮书)。通过集成Chrome浏览器渲染引擎与MCP协议,我们成功将采集成功率提升至99.2%。这套MCP-web-capture系统究竟如何突破动态渲染与反爬限制?本文将揭晓其技术架构与实战应用。
如何使用
- 项目地址:gusibi/mcp-web-capture
- 克隆代码仓库:
git clone [email protected]:gusibi/mcp-web-capture.git
- 安装 Python 依赖:
cd mcp-server
pip install -r requirements.txt
加载 Chrome 扩展:
- 打开 Chrome,访问
chrome://extensions - 启用"开发者模式"
- 点击"加载已解压的扩展程序",选择 chrome-extension 目录
- 打开 Chrome,访问
启动后端服务:
cd mcp-server
python main.py
配置 Chrome 扩展:
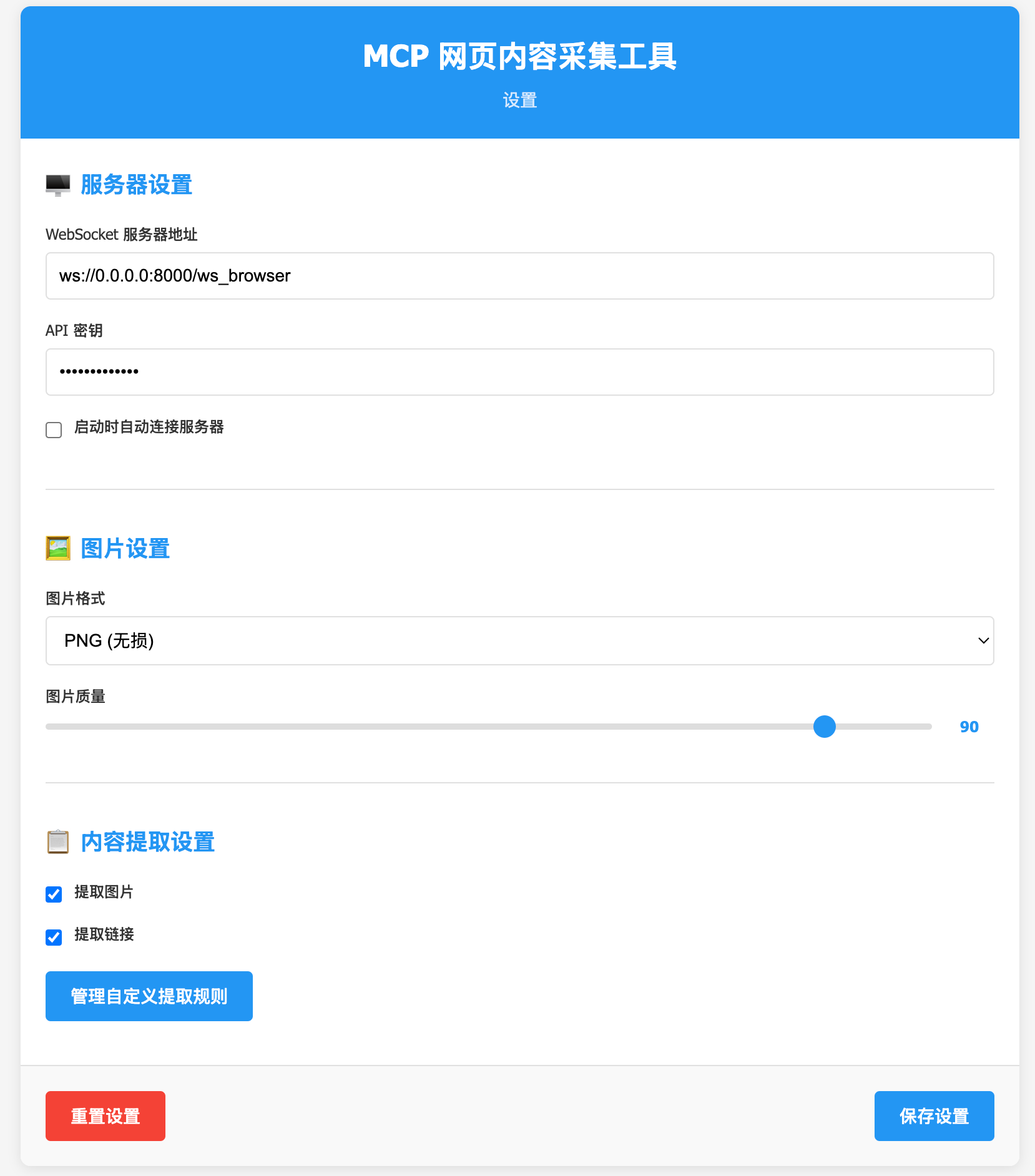
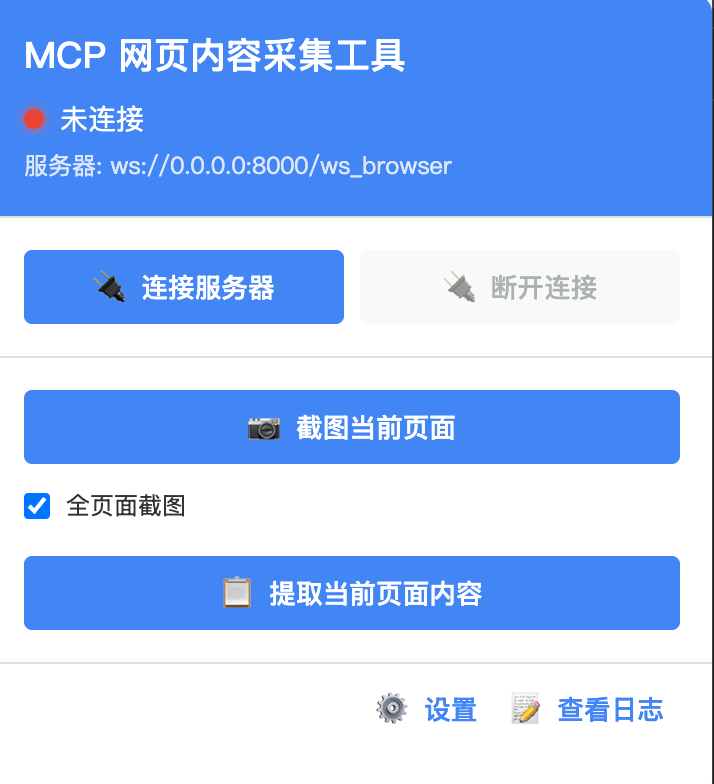
- 点击浏览器工具栏中的 MCP 图标
- 在设置页面配置 WebSocket 服务器地址
- 设置安全密钥(需与后端配置一致)
- 在插件中点击连接服务
在 cline 中添加 MCP server,服务地址是 http://0.0.0.0:8000/mcp
- 配置后可以输入 “抓取 http://onlinestool.com 页面内容“
以下是一个示例,可以看到成功抓取了内容。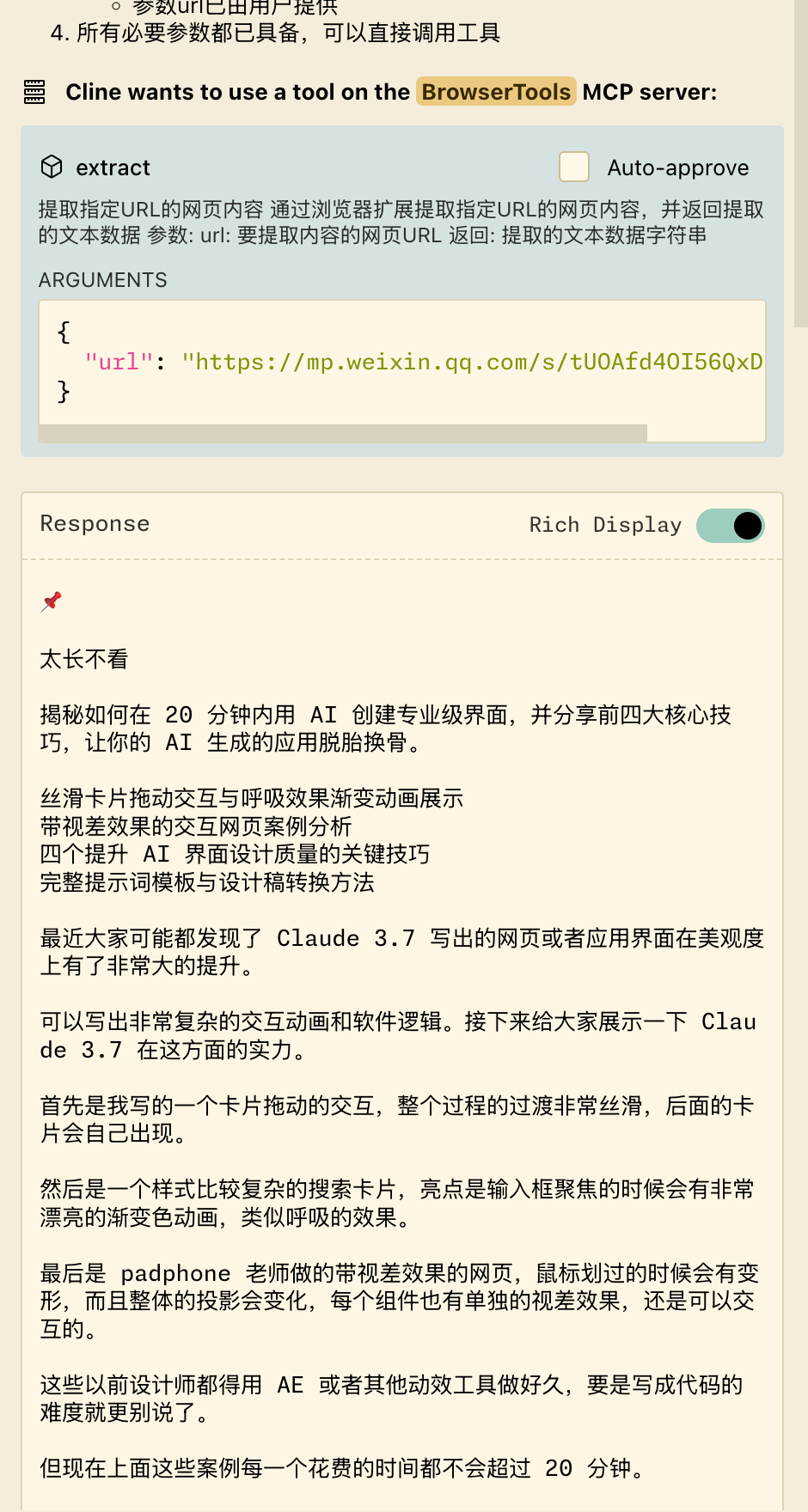
什么是 MCP
MCP(Model Control Protocol) 是一种用于 AI 模型交互与控制 的通信协议,通常用于客户端(如浏览器、应用程序)与 AI 服务(如 LLM 大语言模型、计算机视觉模型等)之间的 指令传递、数据交换和状态管理。
MCP-WEB-CAPTURE 可以做什么
mcp-web-capture 工具是一个网页内容采集系统,由 Chrome 浏览器扩展和 Python 后端服务组成,用于AI MCP 自动化网页内容获取和处理。
开发 MCP-web-capture 的目的是为了抓取 微信公众号文章,无论是使用 jina、firecrawl 还是 water crawl 抓取微信公众号内容失败率都很高,为了能够成功提取内容,就采用了浏览器插件的形式,保证一定能成功。
系统架构
MCP 采用客户端-服务器架构,主要由两部分组成:
- Chrome 浏览器扩展:作为前端客户端,负责网页访问、内容渲染和数据采集
- Python 后端服务:作为 MCP 服务器端,负责任务调度和结果处理
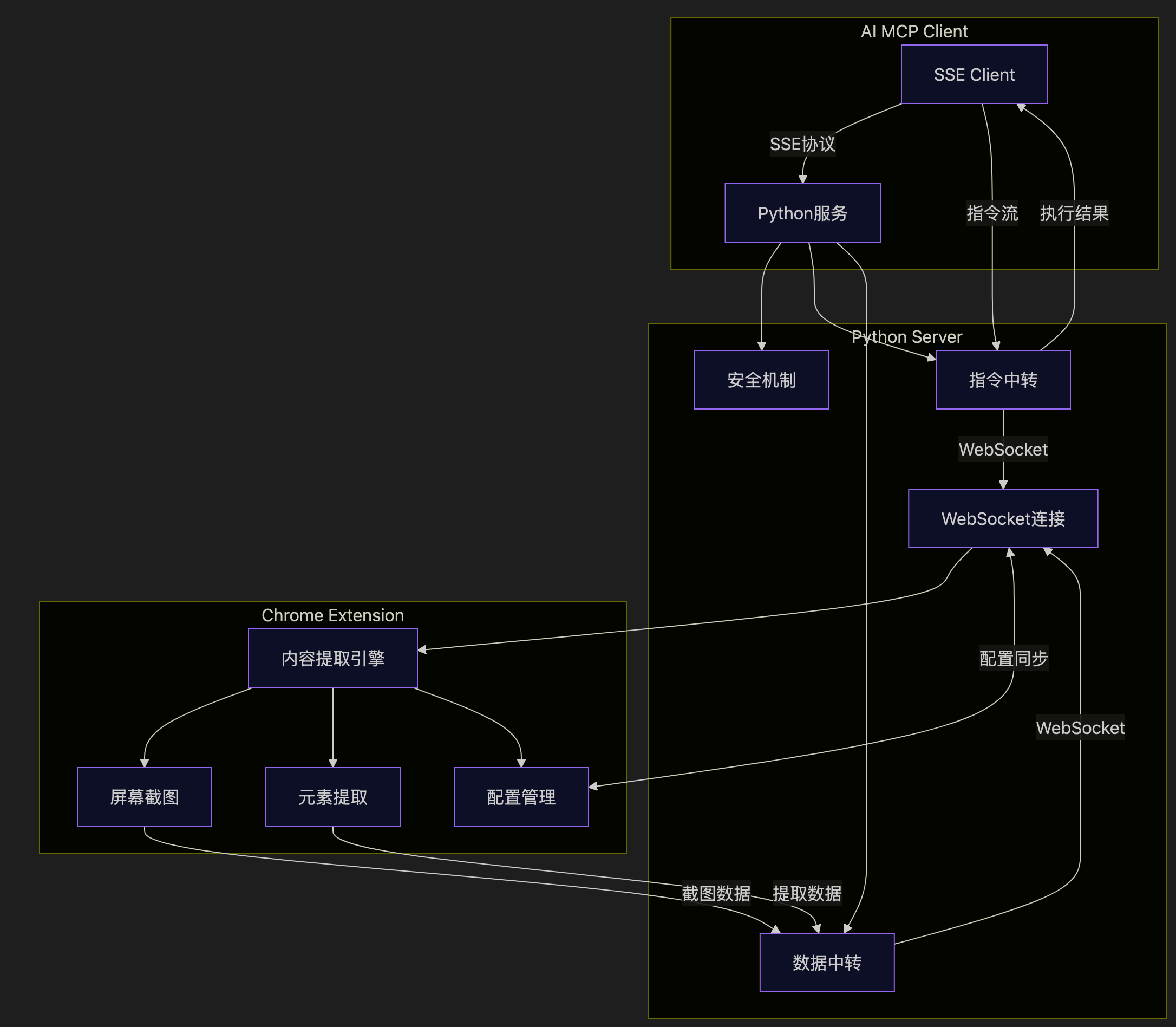
这种架构设计使 MCP 能够充分利用浏览器的渲染能力和 Python 的数据处理能力,实现高效且可靠的内容采集。
Chrome 扩展组件详解
Chrome 扩展是 MCP 系统的用户界面和数据采集终端,提供了一系列强大功能:
WebSocket 连接管理
扩展通过 WebSocket 协议与后端服务建立长连接,实现实时通信:
- 持久性连接确保命令能够实时传递
- 支持自动重连和连接状态监控
- 视觉化连接状态显示,便于用户了解系统运行情况
网页内容处理
作为核心功能模块,它提供了多种内容获取方式:
- 网页截图:支持全页面或选定区域的高质量截图
- 智能内容提取:自动识别页面主要内容区域,提取结构化数据
配置管理
用户友好的设置界面,让非技术用户也能轻松配置:
- WebSocket 服务器连接设置
- 安全认证密钥配置
- 内容提取规则自定义[TODO]
Python 后端服务详解
Python 后端是 MCP 系统的指挥中心,负责任务分发和结果处理:
通信协议
自定义的 MCP 协议基于 WebSocket,实现了高效的双向通信:
- 支持多客户端并发连接
- 定义了标准化的请求/响应格式
- 实现了心跳机制确保连接稳定性
指令管理系统
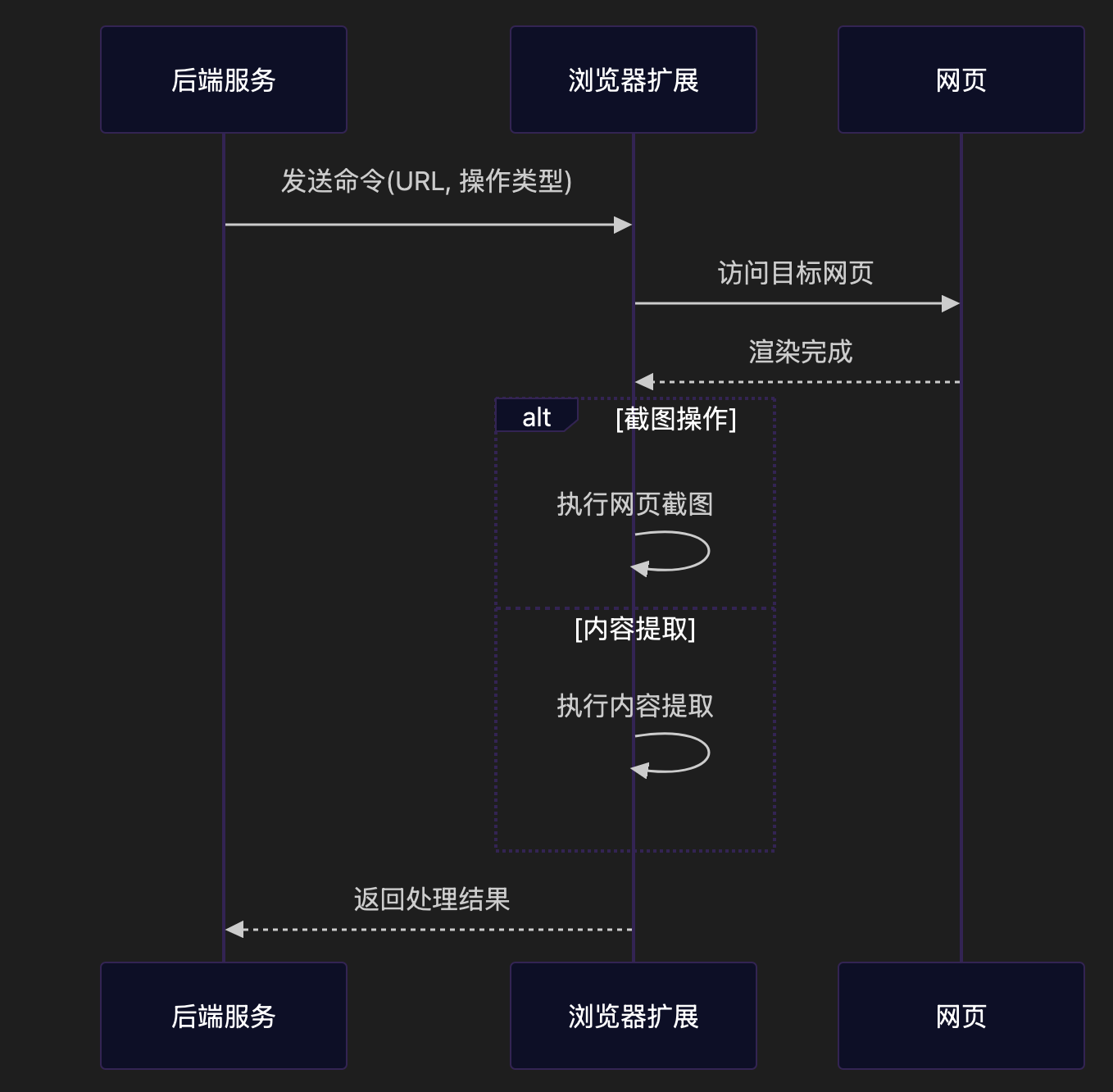
后端服务支持多种内容采集指令:
capture命令:指定 URL 进行截图,返回图片存储路径extract命令:指定 URL 提取内容,返回结构化数据
数据处理流水线
灵活的数据处理机制,支持多种后续操作:
- 图像处理:支持图像压缩、裁剪和格式转换
- 内容解析:使用 BeautifulSoup4 和 lxml 进行 HTML 解析
- 可扩展插件系统:支持自定义处理逻辑的集成
项目结构与技术栈
MCP 项目采用模块化设计,清晰的目录结构便于维护和扩展:
Chrome 扩展目录结构
chrome-extension/
├── manifest.json # 扩展配置文件
├── background.js # 后台脚本
├── popup/ # 弹出窗口
├── options/ # 选项页面
├── content/ # 内容脚本
├── lib/ # 功能库
│ ├── websocket.js # WebSocket 连接管理
│ ├── capture.js # 截图功能
│ ├── extractor.js # 内容提取功能
│ └── logger.js # 日志记录功能
├── logs/ # 日志模块
└── offscreen/ # 离屏渲染模块
Python 后端目录结构
mcp-server/
├── requirements.txt # 依赖包列表
├── config.py # 配置文件
├── main.py # 主服务器入口
├── mcp_protocol.py # MCP 协议处理
├── websocket_manager.py # WebSocket 管理
├── logger.py # 日志模块
├── decorators.py # 装饰器
└── handlers/ # 请求处理器
├── __init__.py
├── capture_handler.py # 截图处理器
└── extract_handler.py # 内容提取处理器
技术栈选择
MCP 项目采用现代技术栈构建:
- 前端: JavaScript (ES6+), HTML5/CSS3, Chrome Extension API
- 后端: Python 3.10+, FastAPI, asyncio
- 通信: WebSocket, 自定义 MCP 协议
- 数据处理: BeautifulSoup4, lxml, Pillow
- 安全: cryptography 库
使用场景与应用价值
MCP 系统适用于多种网页内容采集场景:
市场研究与竞争分析
- 自动收集竞争对手产品信息和价格变化
- 跟踪行业趋势和新闻动态
- 生成结构化市场报告
内容聚合与分发
- 构建定制化内容聚合平台
- 自动收集和整理特定主题的文章
- 多源数据的统一处理和转换
自动化测试与监控
- 网页视觉变化监控
- 跨浏览器兼容性测试
- 用户界面自动化测试
数据科学与分析
- 构建机器学习训练数据集
- 网页内容时序分析
- 大规模网络数据挖掘
安装与配置指南
前置要求
- Python 3.10+
- Chrome 浏览器
未来发展计划
MCP 项目正在积极开发中,计划添加以下功能:
扩展提取规则配置
- 可视化规则编辑器
- 基于 AI 的自动规则生成
分布式采集集群
- 多节点协同工作
- 负载均衡和任务分发
数据处理管道增强
- 内置数据清洗工具
- 更多导出格式支持
API 接口扩展
- RESTful API 支持
- 第三方系统集成能力
结语
MCP 工具通过结合 Chrome 浏览器扩展和 Python 后端服务的优势,提供了一个强大而灵活的网页内容采集解决方案。无论是数据分析师、内容聚合平台开发者还是自动化测试工程师,都能从这个工具中获益。
该项目采用 MIT 许可证开源,欢迎社区贡献和改进。如果您对该项目感兴趣或有任何问题,请访问项目 GitHub 仓库或提交 Issue。


